Next: About this document ...

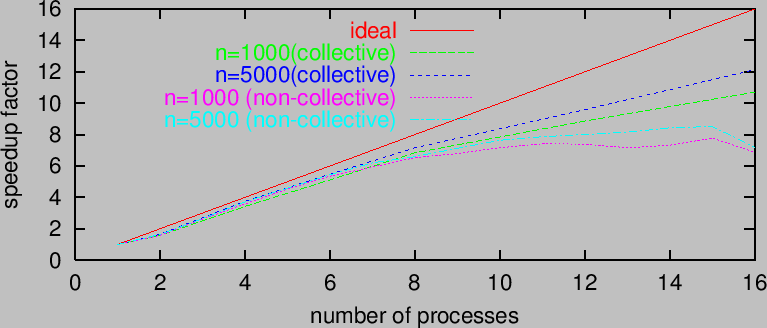
Real speedup by parallelism
Each process can communicate with any other process on MPI
![]() Collective operations similar to
Collective operations similar to
MPI_Bcast and
MPI_Reduce
An example : the product of dense univariate polynomials with 3000bit coefficients
Algorithm(Shoup) : FFT+Chinese Remainder
Communication cost :
 with collective operations
with collective operations
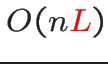 without collective operations
without collective operations
(![]() : number of processes,
: number of processes, ![]() : degree)
: degree)
=17cm