




: 割算アルゴリズム
: 割算アルゴリズムとグレブナ基底
: Initial term の取り出し
目次
索引
前の節の二つの関数 in(F) および in2(F) には違いがないと
思うかもしれないが,
次の関数で実行時間をはかるとおおきな違いがある.
def test1() {
F = (x+y+z)^4;
for (I=0; I<1000; I++) G=in(F);
return(G);
}
def test2() {
F = (x+y+z)^4;
for (I=0; I<1000; I++) G=in2(F);
return(G);
}
|
[764] cputime(1);
0
0sec(0.000193sec)
[765] test2();
[z^4,1,z^4]
0.06sec + gc : 0.08sec(0.1885sec)
[766] test1();
[x^4,1,x^4]
0.2sec + gc : 0.08sec(0.401sec)
|
test1 と test2 では, 3 倍ちかくの実行時間の差がある.
これはどういった理由からであろうか?
理由を理解するには計算機のメモリに多項式がどのように格納されているかを
考えてみる必要がある.
Asir では
メモリにたとえば多項式 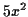 が格納されるときには,
つぎのようなセルとして格納されている.
が格納されるときには,
つぎのようなセルとして格納されている.
| 主変数名 |
x |
| 主変数にかんする次数 |
2 |
| 係数 |
5 |
| 次のモノミアルのアドレス |
なし |
このようなセルの和でモノミアルの和を表現する.
たとえば, 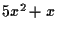 であれば, 次のようなセルの集まりとして
格納されている.
であれば, 次のようなセルの集まりとして
格納されている.
| 主変数名 |
x |
| 主変数にかんする次数 |
2 |
| 係数 |
5 |
| 次のモノミアルのアドレス |
AAAA |
AAAA:
| 主変数名 |
x |
| 主変数にかんする次数 |
1 |
| 係数 |
1 |
| 次のモノミアルのアドレス |
なし |
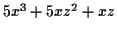 を asir に入力すると,
を asir に入力すると,
[755] 5*x^3+5*x*z^2+x*z;
5*x^3+(5*z^2+z)*x
と 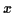 の多項式として表示されるであろう.
メモリ内部には, 上で説明したしたように,
に関するモノミアルを表現するセルのリストとして表現される.
上の説明との違いは,
の係数が,
の多項式として表示されるであろう.
メモリ内部には, 上で説明したしたように,
に関するモノミアルを表現するセルのリストとして表現される.
上の説明との違いは,
の係数が, 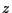 の多項式であり
それが に関するモノミアルを表現するセルのリストとして
表現されているという再帰的構造を持つことである.
図示すると次のようになる.
の多項式であり
それが に関するモノミアルを表現するセルのリストとして
表現されているという再帰的構造を持つことである.
図示すると次のようになる.
| 主変数名 |
x |
| 主変数にかんする次数 |
2 |
| 係数 |
5 |
| 次のモノミアルのアドレス |
AAAA |
AAAA:
| 主変数名 |
x |
| 主変数にかんする次数 |
1 |
| 係数のアドレス |
BBBB |
| 次のモノミアルのアドレス |
なし |
BBBB:
| 主変数名 |
z |
| 主変数にかんする次数 |
2 |
| 係数 |
5 |
| 次のモノミアルのアドレス |
CCCC |
CCCC:
| 主変数名 |
z |
| 主変数にかんする次数 |
1 |
| 係数 |
1 |
| 次のモノミアルのアドレス |
なし |
この表現をみれば,
についての最高次の項を取り出す操作
は 1 ステップで終るのにたいし,
についての最高次の項をとり出す操作は,
の各次数の係数の についての最高次の項を取り出してから,
その中でさらに一番大きいものをとりださねばならないことが
分かるであろう.
こちらの方がはるかに複雑であるので, 時間がかかるのである.
C 言語を知ってる読者は 図 16.1 のような構造体を用いて,
このような多項式の足し算および deg 関数 coef 関数
の実装を試みると理解が深まるであろう.
図 16.1:
多項式を表現する構造体
 |
Asir では, このような表現による多項式を
再帰表現多項式とよぶ.
この型のデータに対して type 関数の戻す値は 2 である.
さて, あたえられた順序に対して, このような多項式の表現法では,
initial term を取り出す効率が順序によりかわってしまうし,
効率の点からは最適な表現とはいえない.
initial term を取り出すには,
多項式は多変数のモノミアルのあたえらた順序に関するリストとして
表現するのがよいであろう.
この表現方法を, asir では, 分散表現多項式
とよんでいる.
たとえば,
多項式
を
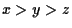 なる lexicographic order での分散表現多項式としてメモリに格納する
ときにはつぎのようなリストとして表現する.
なる lexicographic order での分散表現多項式としてメモリに格納する
ときにはつぎのようなリストとして表現する.
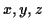 についての次数 についての次数 |
[3,0,0] |
| 係数 |
5 |
| 次のモノミアルのアドレス |
DDDD |
DDDD :
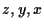 についての次数 についての次数 |
[1,0,2] |
| 係数 |
5 |
| 次のモノミアルのアドレス |
EEEE |
EEEE :
| についての次数 |
[1,0,1] |
| 係数 |
1 |
| 次のモノミアルのアドレス |
なし |
次の関数では, initial term の取り出し 1000 回のテストを,
分散表現多項式に対しておこなっている.
dp_ptod(F) は F を分散表現多項式に変換する関数である.
詳しくはマニュアルを参照.
def test1_dp() {
F = (x+y+z)^4;
dp_ord(2);
F = dp_ptod(F,[x,y,z]);
/* print(F); */
for (I=0; I<1000; I++) G=dp_hm(F);
return(G);
}
|
とりだしにかかる時間は以下のとおりである.
[778] test1_dp();
0.01sec(0.01113sec)
|
: 割算アルゴリズム
: 割算アルゴリズムとグレブナ基底
: Initial term の取り出し
目次
索引
Nobuki Takayama
平成15年9月12日