2020.12.21 QA プログラム関連
UTF8 漢字コードでテキストファイルを作れません.
ファイルは 1byte (16進数2桁, 2進数8桁) の数の列です.
fputc 関数も 1byte づつ書き込みます.
たとえば "こ" の UTF8 コードは
0xe3811a と 16進数6桁なので, 3 byte です.
したがって,
fputc(0xe3,fp);
fputc(0x81,fp);
fputc(0x8a,fp);
のように書く必要があります.
"おは" とファイル tt.txt へ書き込む完成形のプログラムは
#include <stdio.h>
int main() {
FILE *fp;
int c;
fp = fopen("tt.txt","w");
/* "お" の utf-8 code は e3818a */
fputc(0xe3,fp);
fputc(0x81,fp);
fputc(0x8a,fp);
/* "は" は e381af */
fputc(0xe3,fp);
fputc(0x81,fp);
fputc(0xaf,fp);
fclose(fp);
return(0);
}
fputc(0xe3818a,fp); としてもファイルへ 3 bytes のデータが書き出される
わけではありません.
コード表の見方:
一番左の数に一番上の数を足したものが求めるコード.
たとえば
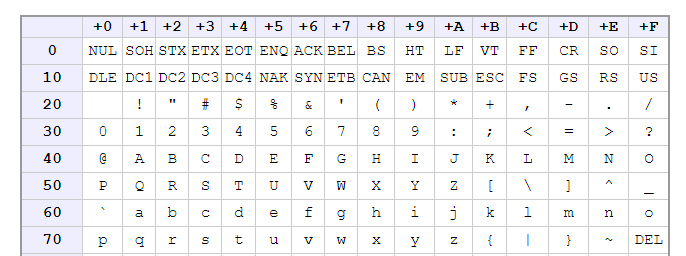
で "A" の字は "40" 行目の "+1" 列にあるので 0x41 がコード.
"z" の字は "70" 行目の "+A" 列にあるので 0x7a がコード.
参考:
ちなみに同じような形式で画面に書き出すには
fp = fopen("tt.txt","w");
を
fp = stdout;
として, fclose(fp) の行を削除します.
stdout は stdio.h で予め定義されている標準出力(標準状態では画面)
を意味します.
もちろんたとえば fputc(0xe3,fp) を
printf("%c",0xe3); と書き直しても標準出力へ出力されます.
char s[10] の 10 は何?
char 型(1 byte)を 10 個確保.
s[0], s[1], ..., s[9] でそれぞれを読み書きできる.
asir のベクトル S = newvect(10) とほぼ同様.
初期化は 10 個全部指定してもいいし, 最初の数個のみの指定でもよい.
たとえば
char s[10]={0x41,0x42};
は s[0], s[1] のみ初期化.
確保した量より多いデータを右辺で指定してはいけない.
例:
char s[3]={0x41,0x42,0x42,0x44};
は右辺で 4bytes のデータを与えているので, だめ.
C言語で整数を扱うには?
実習で使ってるシステムでは int 型は 32 bit までの数しか扱えずさらに
${\bf Z}/m {\bf Z}$, $m=2^{32}$ での計算しかできません.
整数を扱う話題は
大学院の講義 (5/21, 5/28) で解説しています.